Anything bad that can happen — will happen. This old adage applies 100% to the technology industry, where crashes and outages are far more common than the sales and marketing teams would want us to think. However, DevOps engineers who deal with infrastructure know how hard it is to ensure everything works as intended all of the time — and to configure monitoring that actually keeps track of a system’s health and helps prevent crashes and downtime.
At StatusGator we monitor the status pages of more than 2,800 cloud-based services and deliver instant notifications to our users. We have mountains of data on downtime and outages and see the full picture, so we decided to make a quarterly top downtime list. We hope our findings will motivate DevOps engineers to see how others deal with service outages so they can improve their own reliability.
Read on to find out about the five biggest outages of Q2 2020 and how Slack, Zoom, GitHub, IBM Cloud and T-Mobile acted during these crises. We also rate the outcomes of these outages and would be glad to hear your thoughts on our ratings.
Outage #1 – Worldwide Slack outage, May 12, 2020
Slack is the primary means of communication for thousands of companies worldwide, so its stable uptime is a matter of utmost importance. Thus, when users stopped being able to send and receive Slack messages around 7:30 PM EDT, the situation quickly escalated into a full-scale problem. Unlike during previous outages, this affected the entire Slack ecosystem: nobody could log in to Slack or receive any notifications. “Is Slack down?”, the users asked themselves and the answer was an undeniable “Yes!”
Anyone using the Slack Electron app was getting a generic HTTP error. Even the next day, after the issue had been resolved, people using the Slack app were still seeing the same error message. The app doesn’t refresh automatically so it was confusing for non-technical users, many of whom didn’t know they had to press Ctrl-R to refresh the app and restore service after the error.
The company confirmed they were aware of the situation and posted regular updates to the Slack status page. Quite importantly, these updates were not standardized ‘we are aware of the situation, please stand by’ responses.
Team representatives wrote detailed messages that showed customers the Slack team was transparent about the challenge they faced and the efforts they made to overcome it.
At 10:26 PM EDT Slack reported full restoration of services and apologized for the inconvenience once again. Even more importantly, they published a detailed postmortem on Medium, explaining the reasons behind the issue, the actions they performed to overcome it, the conclusions they came to, and the measures they were undertaking to eliminate the chance of a similar situation happening again.
Feel free to read this postmortem, it is very technical yet quite understandable even for laypersons. Slack demonstrates here that they care about members of their user base — both developers and the mass user base, and the confidence this article projects is admirable.
An important thing to note here is that while the issue itself started at 8:30 AM EDT, the issue went completely under the radar till around 7:30 PM EDT when multiple users reported issues with Slack. They reported them inside the app (which was mostly down by that time), on Twitter, on Downdetector, on the Slack website (which went down too quite soon), and through many other channels, before the Slack team became aware of the situation.
Getting notified about an outage would have been much faster and easier with StatusGator, where you can aggregate multiple status pages into one dashboard. StatusGator can send centralized notifications on downtimes for any services and APIs, and you can enjoy it with a free subscription plan!

Outage #2 – Zoom shutdown, May 17, 2020
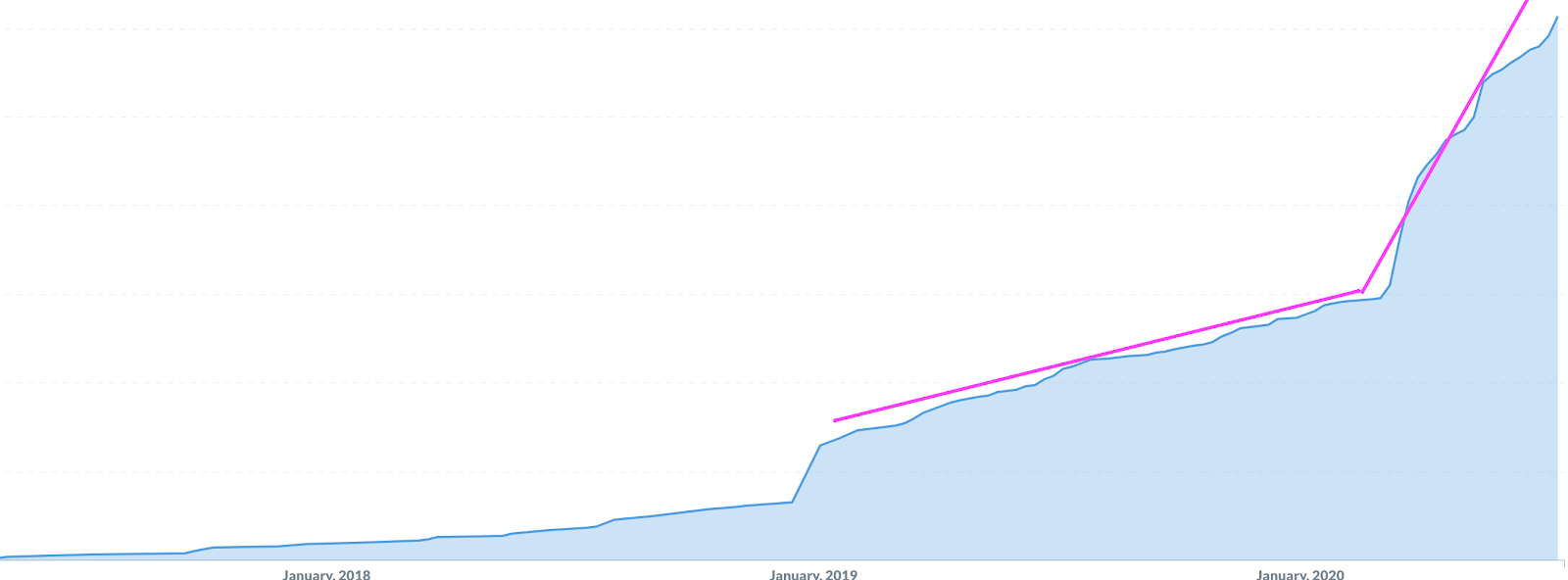
Zoom usage has gone up dramatically since the Coronavirus pandemic began as more people work and study remotely. So have subscriptions to the Zoom status page, which has skyrocketed in StatusGator since April.
Aside from businesses being forced to begin working remotely, many churches and other public organizations started using Zoom to hold Sunday masses, and meetings, and to host public events. Thus, while Sunday is not a business day, many paid accounts in the UK quickly noticed that they were not able to host or join Zoom meetings (free accounts seemed not to be affected). The issue was reported through multiple channels, including Twitter and StatusGator which monitors the status of Zoom.
A Zoom spokesperson responded, acknowledging awareness of the situation and mentioning it was only affecting a subset of users. However, we all know a subset might be 1% or 99% and Zoom provided no indication whatsoever as to the volume of users affected. Providing more transparency into the percentage of affected users is a hallmark of a quality status page, something Zoom should improve.
The issue was reported resolved by 11:40 AM EDT, but Zoom provided no explanation or postmortem of any kind. Such an attitude, along with Zoombombing and a “Company Directory” checkbox in settings allowing users to leak corporate photos and emails is one of the reasons many users are now actively seeking better alternatives to Zoom.
Outage #3 – GitHub was inaccessible… Again. June 29, 2020
GitHub seems to be down a lot more since its $7.5 billion acquisition by Microsoft. The reasons have not been disclosed, and we can only speculate on the causes. Maybe it has something to do with integrating GitHub infrastructure with Microsoft systems. Maybe it’s because GitHub has been moving faster and adding more features. In any case, it’s been almost two years since the acquisition, and users are noticing more sustained periods of downtime at GitHub. Our independent analysis of the GitHub status page confirms that the outages have become more frequent over the past two years.
Microsoft is working hard to turn GitHub into an even better place for developers than it was before. The Redmond giant made all of the paid plans more affordable earlier this year and offered some key features for free to place more tools at the disposal of IT professionals. Microsoft, Apple, AWS, Google, Facebook, and thousands of other companies use GitHub to store and run their code repositories, so its uptime is of utmost importance.
Nevertheless, GitHub was down for two hours on June 29, 2020. The entire website and its services were inaccessible, so many developers were not even able to push code or deploy their apps due to the number of GitHub integrations that were unresponsive. Naturally, this caused a major backlash and caused GitHub to introduce a monthly availability report in addition to its status page, providing detailed explanations of the reasons and outcomes of every outage.
Outage #4 – IBM Cloud went down along with the status page, June 10, 2020
One of the biggest mistakes any cloud-based service can make is to host its status page on its own infrastructure. It appears IBM Cloud did just that, so when its whole infrastructure became inaccessible for several hours in June, its status page followed suit. We could have expected IBM to draw some conclusions after the Dallas downtime this March, but, apparently, they did not bother, or did not make enough effort.
Thus, on June 10, 2020, the IBM Cloud infrastructure went down globally. This outage rendered features like Watson AI, IBM Cloud Foundry, Kubernetes Service, Cloud Object Storage, Identity Access and Management, VPN for VPS, App Connect, and others completely inaccessible. Fortunately, the IBM Cloud status page was unavailable only in the early stages of the outage and became available intermittently later. That’s why StatusGator was still able to send alerts to users who had subscribed to the IBM Cloud status page.
The company totally failed to communicate the reasons for the outage, as well as the steps it took to alleviate the impact. It later became known from an independent monitoring service, that a 3rd-party network provider had extensively used the traffic routes, which resulted in severe constraints on the IBM Cloud configuration bandwidth. IBM specialists reconfigured their systems and restored operations, but no official explanations or announcements ensued — much to the disappointment of users.
It is not the first time IBM has failed at public relations, nor, do we think, will it be the last. This is probably one of the reasons for them to fall so far behind AWS, Google Cloud Platform, Microsoft Azure, and other cloud providers, despite delivering a diverse range of competitive cloud services.
But what could IBM have done? Had an independent status page, naturally! Below are just some of the variants they could have used:
- StatusPage.io. The largest and most popular platform around. This is probably the only provider big enough to handle companies like IBM Cloud.
- Status.io. Another large and widely used status page provider with infrastructure meeting the scale that IBM Cloud would require.
- Alternatively, they could build their own status page, being careful not to be dependent on any of their own infrastructure. IBM could host it as a static page on a third-party CDN to reduce complexity and dependency on its network.

Outage #5 – T-Mobile Flushes Its Network Down the Drain, June 15, 2020
T-Mobile, one of the largest mobile network operators in the US, the EU and the UK, recently found itself amid a perfect storm, when it failed to provide voice and text messaging for 13 hours straight across the US. According to outside observer Matthew Prince, CEO @ Cloudflare, “T-Mobile has made some changes to their network that went badly and resulted in a series of cascading failures for their users”. He also said that “this disaster was almost certainly entirely of the T-Mobile team’s own making”.
On the contrary, Neville Ray, T-Mobile’s President of Technology, tweeted that while this was indeed a ‘major issue affecting voice and text services for users across the country’, it originated from a faulty 3rd-party provider’s system and T-Mobile’s engineers were working hard to fix it. He later elaborated on the topic in a detailed blog post with explanations regarding the causes of the outage.
To quote Mr Ray, ‘the trigger event is known to be a leased fiber circuit failure from a third-party provider in the Southeast. This is something that happens on every mobile network, so we’ve worked with our vendors to build redundancy and resiliency to make sure that these types of circuit failures don’t affect customers. This redundancy failed us and resulted in an overload situation that was then compounded by other factors.‘ This resulted in overloading the IP pools and crashes across all regions in the US.
As a result of not being able to reach most services, T-Mobile customers started reporting unavailability of Facebook, Instagram, and other platforms, while it was their mobile carrier network that was actually offline. Business Insider reported that while T-Mobile customers blamed AT&T and Verizon for failures, both carriers operated under normal load levels. However, the aforementioned post by Neville Ray stated that T-Mobile is undertaking all necessary measures to ensure the impossibility of such occurrences in the future by building double resilience and redundancy measures for all its core systems.
As you can see, the company’s inability to articulate its position clearly, unwillingness to accept responsibility for failure from the start and lack of transparency in the aftermath of the outage did not allow T-Mobile to walk out of the situation without any stains. It even resulted in rumors of a massive DDoS attack they faced and failed to repel.
Forecast for Q3 outages
We have named only the five biggest network outages of Q2 2020, but there were many, many, more. The Microsoft Azure Central India region was offline for many hours on May 18 and 19 due to a power grid failure and subsequent air cooling unit shutdown. Cloudflare suffered a major outage affecting millions of websites after a technician unplugged a crucial panel while patching was in progress on April 16, 2020.
While the summer is in the middle and Q3 is young, we do not know what will go ‘boom’ next time or when and where it might happen. However, we already know Cloudflare experienced a big outage on July 17, 2020, and we will cover it in more detail in our next digest. We can also predict that IBM is not going to make a reliable status page ?♂️ — and that T-Mobile will not even bother making one! ?♂️ Prove us wrong!
StatusGator awards for Q2 contestants
Let’s rate these downtimes based on their discovery, communications from the companies involved and the outcomes of each event:
| Company | Status page | Postmortem | Communication | Result |
| Slack | ? Online | ? In detail | ? Constant | ?♂️ Superhero |
| Zoom | ? Online | ? Minimal | ? Minimal | ☹️ Reputation Suffering |
| GitHub | ? Online | ? Monthly | ? Excellent | ? Good Recovery |
| IBM Cloud | ? Offline | ? None | ? None | ? Facepalm |
| T-Mobile | ❌ None | ? Contradictory | ? Reluctant | ? Finger Pointer |

Shit happens, but a status page can help negate its impact
We are sure outages big and small will continue to take place due to human error, faulty design, untested redundancy, or even the weather. We are also sure that using a centralized status page reporting service like StatusGator can help you discover and identify issues faster, mitigate their consequences sooner and better, and keep your customers informed to minimize their distress and frustration.
What to do next?
- Set up a status page if you don’t have one yet
- Subscribe to StatusGator and configure your service downtime notifications — it’s free!
- A few more articles on status pages:
- Your Status Page Is Awesome!
- Embed Your Status Page Everywhere
- Your Status Page Deserves Its Own Domain
- 25 Best Status Page Examples
- 7 Status.io Alternatives for Better Incident Communication
- 23 Facts on GitHub Reliability in 2023
- 7 Statuspage.io Alternatives
- CircleCI Outages: Have They Kept Their Promise in 2022?
- How Did Slack Perform a Year After the Acquisition by Salesforce?
P.S. Special thanks to DevOps Chat for helping us to improve this article.