Modern infrastructure is no longer just about what you build and run internally.
Most DevOps and system administration teams rely on a growing number of external SaaS services, including cloud providers, monitoring tools, authentication systems, CI/CD platforms, communication tools, and more. When one of these services fails, your application may still look healthy internally, while users are already experiencing issues.
That leads to a common operational question:
How do you monitor external SaaS service outages, and how much value does it add in day-to-day work?
This is a recurring topic in communities like r/devops, r/ITmanagers and r/sre. The approaches typically fall into three categories: manual tracking, DIY monitoring, and dedicated SaaS outage monitoring tools.
Approach 1: manual monitoring (Google alerts + status pages)
The simplest approach teams often start with is manual monitoring:
- Google Alerts for vendor outage keywords
- Subscribing to individual SaaS status pages
- Manually forwarding updates into Slack or email channels
Pros
- Free and easy to set up
- No engineering effort required
Cons
- High noise and irrelevant alerts
- Easy to miss critical updates
- Requires constant maintenance
- No unified view across services
This approach works at very small scale, but quickly becomes unmanageable as the number of dependencies grows.
Approach 2: DIY monitoring (Prometheus + Blackbox Exporter)
More mature teams often move toward internal monitoring setups:
- Prometheus
- blackbox-exporter
- Alertmanager
- Slack or Teams notifications
This approach allows teams to probe external endpoints and detect failures programmatically.
Strengths
- Flexible and customizable
- Works well for controlled health checks
- Integrates with existing observability stacks
Limitations
- Requires ongoing maintenance and tuning
- Needs careful setup for geographic diversity
- Doesn’t inherently understand vendor-specific outages
- Still requires manual interpretation of failures
While powerful, this approach introduces operational overhead that grows with scale.
Approach 3: status page + Slack integration
A very common lightweight approach is:
- Subscribing to SaaS status pages
- Forwarding updates into Slack channels
- Relying on teams to interpret impact manually
This is often the “default” setup in many organizations because it is easy and requires no infrastructure.
However, it has clear limitations:
- No consolidation across vendors
- Duplicate or fragmented updates
- No prioritization or filtering
- No unified incident view
StatusGator has an integration with Slack, where users modify their alerts to stay on top of the third-party SaaS outages without the noise.
Approach 4: automated SaaS outage monitoring with StatusGator
This is where StatusGator comes in.
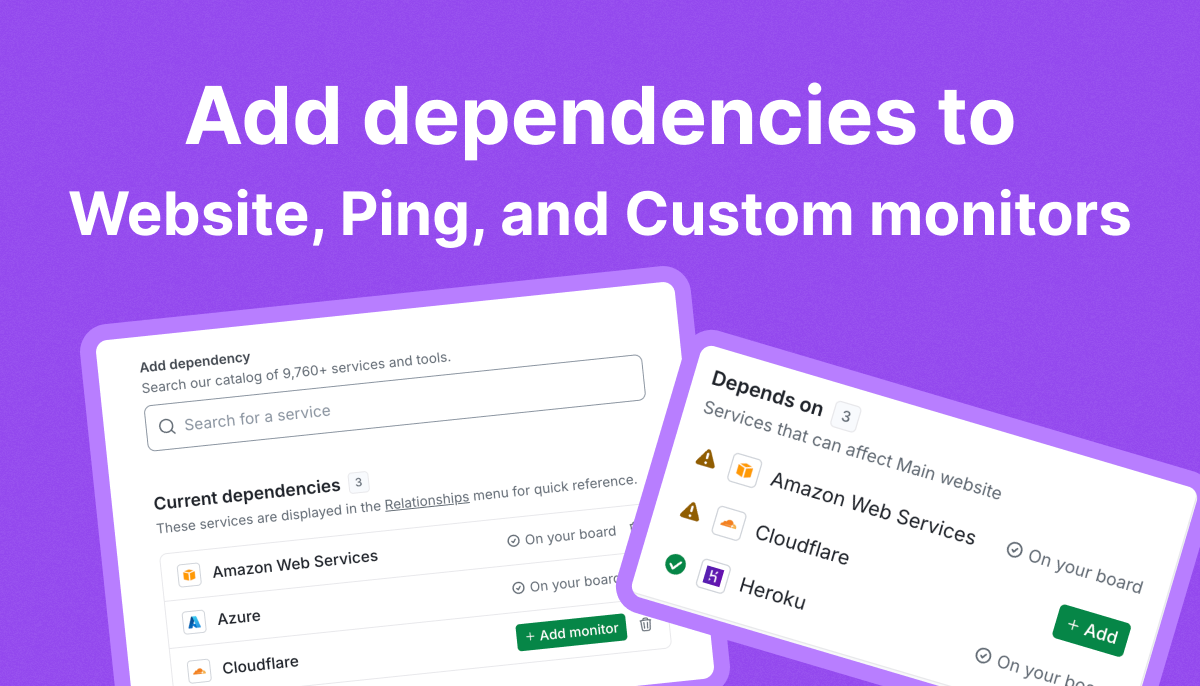
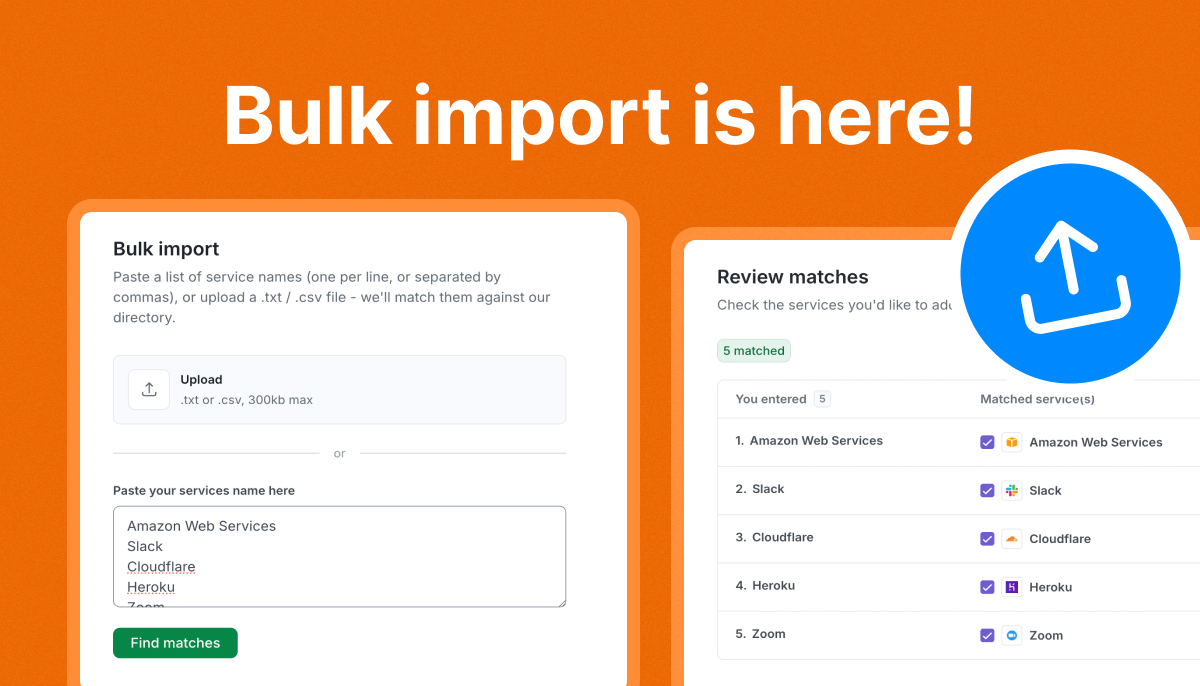
StatusGator is not just a status page tracker. It is a SaaS dependency intelligence system.
Instead of manually monitoring dozens or hundreds of services, StatusGator aggregates and normalizes outage information across your entire SaaS stack.
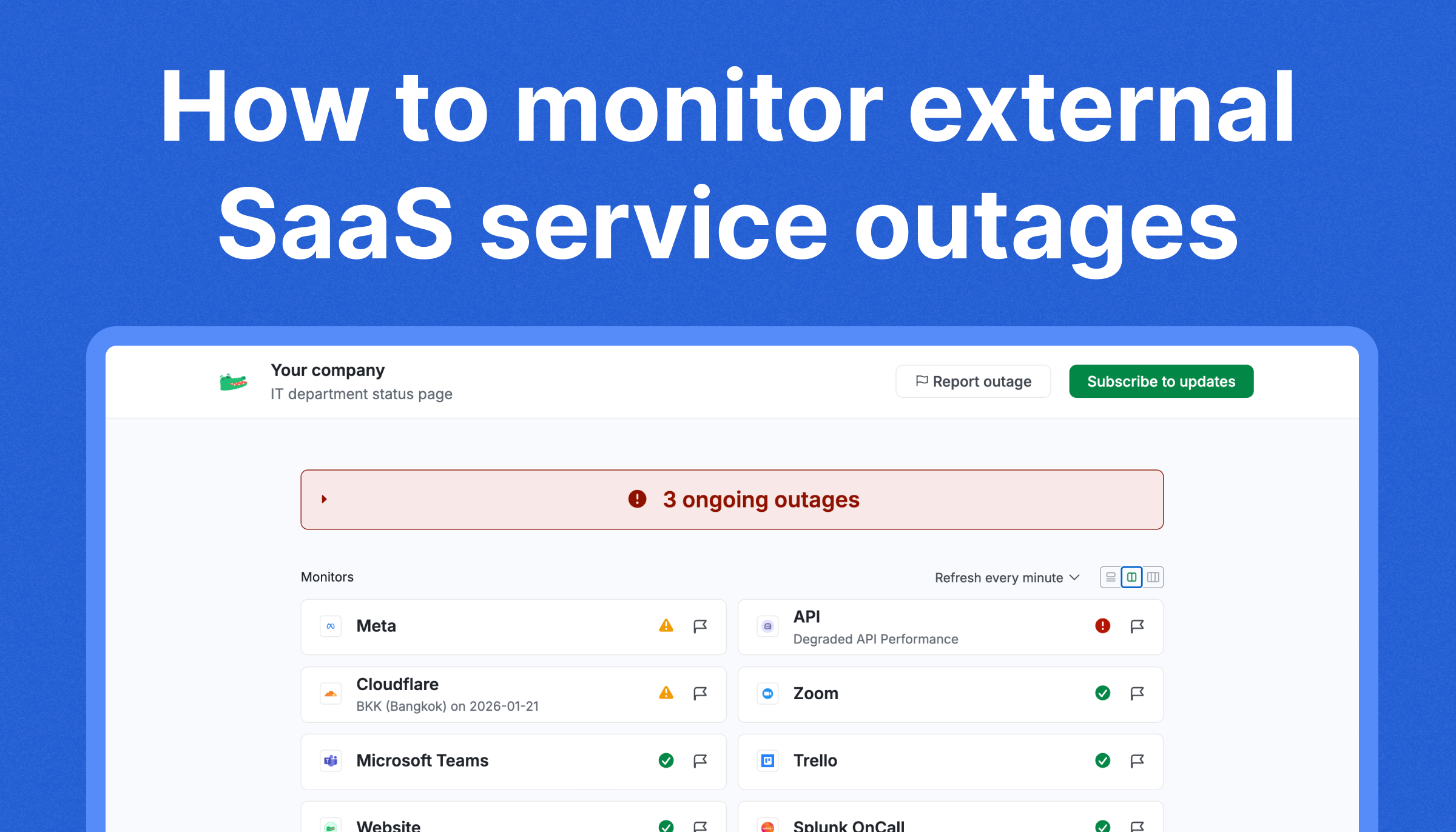
What StatusGator provides
- Monitoring of 7,000+ SaaS services
- Aggregated incident detection from official status pages
- Early Warning Signals
- Real-time alerts to Slack, email, or webhooks
- Incident aggregation across multiple providers
- Historical reliability tracking for SaaS vendors
Enterprise capabilities
For larger or more complex environments, StatusGator also supports:
- Private status ingestion (Enterprise feature)
- Monitor internal or API-based service health signals (e.g. Microsoft 365, Zendesk, Cisco Meraki)
- Centralized visibility across both public and private services
- Structured incident timelines for faster understanding of vendor impact
Why teams move away from manual and DIY approaches
Across DevOps and system administration teams, the same pattern emerges:
- Manual monitoring doesn’t scale
Google Alerts and status page subscriptions quickly become unmanageable.
- DIY monitoring adds operational overhead
While powerful, it requires infrastructure maintenance, tuning, and ongoing ownership.
- Fragmented alerts slow down response
Teams still spend time piecing together what is actually happening across multiple sources.
Where StatusGator fits
StatusGator is designed to remove that operational burden by providing:
- A centralized view of external SaaS dependencies
- Normalized and deduplicated incident information
- Faster awareness of vendor outages affecting production
- Historical context for recurring reliability issues
Summing up
Monitoring external SaaS service outages is no longer optional for modern infrastructure teams. It is part of everyday operational awareness.
Manual tracking and DIY monitoring can work in small environments, but they quickly become difficult to maintain as the number of SaaS dependencies grows.
For most teams beyond small scale, these approaches break down quickly. Instead, StatusGator aggregates status page updates from multiple SaaS providers into a single view. It provides a centralized, scalable alternative without requiring teams to maintain their own monitoring infrastructure. It helps DevOps and system administrators stay aware of external outages without adding operational overhead.