On February 10, 2026, Amazon Web Services (AWS) experienced an outage that triggered widespread reports of CloudFront failures and DNS resolution issues. While AWS later acknowledged the incident, StatusGator detected the disruption earlier using Early Warning Signals, giving customers valuable lead time before the provider confirmed anything publicly.
This incident is a strong example of why proactive monitoring matters, especially when a cloud outage ripples across the internet before official status updates appear.
Timeline (UTC)
Here’s how the incident unfolded based on StatusGator outage reports and AWS’s public acknowledgment.
- 20:43: First outage reports hit StatusGator, with early symptoms pointing to CloudFront failures
- 20:52 to 21:05: Reports accelerate globally, including DNS failures, asset loading issues, and intermittent “not found” errors
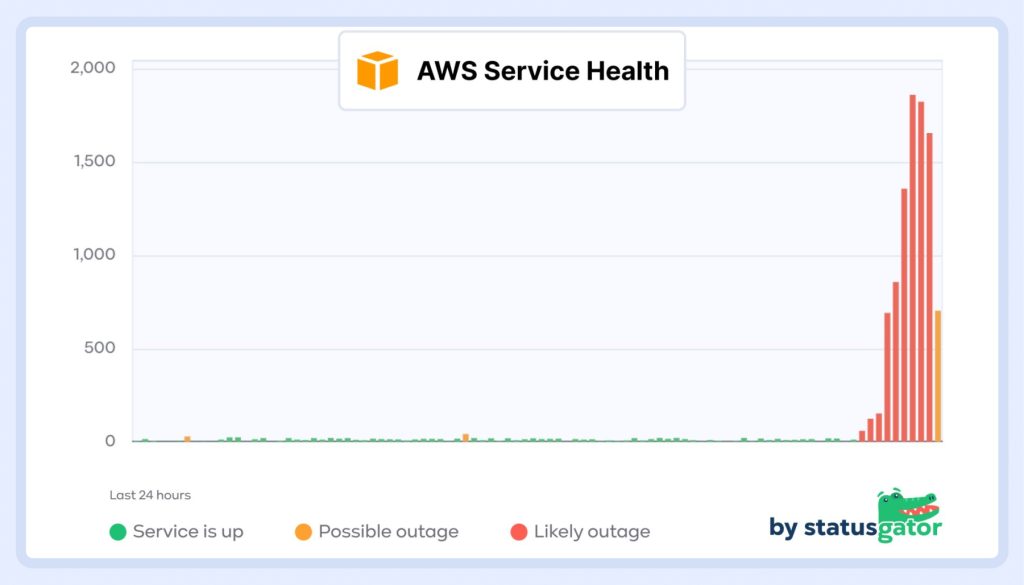
- 21:07: StatusGator sends an Early Warning Signal, indicating abnormal outage activity before AWS posts anything publicly
- 21:15: AWS posts an official acknowledgment on the AWS Health Dashboard, citing DNS resolution failures for some CloudFront distributions
- 21:17 to 21:35: Reports continue from multiple countries, many referencing CloudFront and Route 53 behavior
- 21:47: The last outage reports arrive, suggesting the incident had largely stabilized by this time
Impact
Based on user-submitted reports, the outage looked like a classic edge and DNS disruption.
Users experienced:
- CloudFront intermittently failing to load assets
- DNS resolution failures
- Increased errors and latency
- AWS console login issues
- “Network unreachable” and connectivity failures
These incidents are especially disruptive because they often appear as application-level failures. From an engineering perspective, it can look like your own stack is broken, even when the real cause is upstream.
What users were reporting
StatusGator received outage reports from multiple regions throughout the incident window. Several reports explicitly pointed to CloudFront and DNS.
Here are a few examples:
“cloudfront services are ‘not found’ intermittently but enough to trigger alerting”
“Cloudfront DNS not resolving on AWS”
“Cloudfront issues. Can’t login to AWS Console”
“Route53 or Cloudfront issue”
“cloudfront is returning network unreachable error”
Notably, multiple reports mentioned Route 53 directly, including “route53 flapping,” which aligned with AWS’s later description of DNS resolution failures.
Collateral damage: other services affected
AWS outages rarely stay contained. When CloudFront and DNS resolution degrade, the effects show up immediately in downstream services.
During this incident, users reported issues across other major services, including examples like:
This is a common pattern: customers do not see “AWS is down.” They see their bank app, AI tool, or login system failing.
That’s why upstream visibility matters.
Early Warning Signals triggered before AWS acknowledged the outage
StatusGator began receiving outage reports at 20:43 UTC. AWS did not post a public acknowledgment until 21:15 UTC.
That means StatusGator was collecting real-world outage signals 32 minutes before AWS officially confirmed the incident.
More importantly, StatusGator’s Early Warning Signal triggered at 21:07 UTC, giving customers an 8-minute head start before AWS posted publicly.
That lead time is often the difference between:
- Responding proactively
- Or learning about an outage from customers
User reports provided immediate context about likely root cause
AWS’s initial public note described “DNS resolution failures for some specific CloudFront distributions.”
StatusGator reports, however, surfaced the likely failure mode immediately, with repeated mentions of:
- CloudFront failures
- DNS resolution issues
- Route 53 instability
- AWS console access problems
For teams in incident response, this kind of signal can help cut through noise fast.
Instead of chasing symptoms inside your application, you can quickly narrow the investigation to “AWS edge and DNS.”
Note on AWS Health API vs public status updates
In addition to AWS’s public acknowledgment, StatusGator’s AWS private status integration (via AWS Health) also detected the incident shortly after.
In this case, the AWS Health integration detected a WARN state at approximately 21:17 UTC, which was a couple minutes after the public Health Dashboard update at 21:15 UTC.
This is a useful reminder that even “official” provider notifications, including private integrations, can lag behind real-world impact.
Lessons learned
This outage reinforced a few practical truths about cloud reliability.
Real-world outage signals often appear before official updates
User impact began showing up in StatusGator at 20:43 UTC, well before AWS acknowledged the incident.
For engineering and operations teams, that gap matters.
DNS and CDN failures create confusing symptoms
When CloudFront and DNS resolution are unstable, you may see:
- Broken asset delivery
- Login and authentication failures
- Intermittent “not found” errors
- Partial outages that come and go
These are some of the hardest incidents to diagnose quickly without upstream visibility.
Early detection buys response time, not just awareness
Even 5 to 15 minutes of early warning can be enough to:
- Pause deployments
- Update internal stakeholders
- Reduce alert fatigue
- Communicate with customers before they ask
- Confirm whether an incident is upstream
Try StatusGator for proactive outage monitoring
If your infrastructure depends on AWS, you cannot rely on a single provider status page to tell you when something is wrong.
StatusGator monitors thousands of services and detects outages using Early Warning Signals, so you can know what’s happening before official updates arrive.
Try StatusGator today and get early alerts when your providers go down.