Last checked from Cloud Run official status page 2 min. 51 sec. ago
Cloud Run Status

Is Cloud Run down?
Cloud Run is up
Cloud computing services for business challenges by Google Cloud.
Not working for you?
StatusGator last checked the status of Google Cloud on and the service was operational. There have been 3 user-submitted reports of outages in the past 24 hours.
Cloud Run service health
This chart represents Cloud Run service health over the last 24 hours, with data points collected every 15 minutes based on issue reports, page visits, and signal strength. Sign up for free to see more Cloud Run status data.
24 hrs ending
●
Service up
●
Possible outage
●
Likely outage
Top reported issues
View and upvote the most commonly reported Cloud Run issues to help us better indicate the service status.
- Connectivity issue
- Error message
- Server not responding
- Sign in problem
- Service down
- Slow performance
- Unable to download
- App not loading
- Other
Have a different problem with Cloud Run?
Recent outage reports
See recent outage reports from real Cloud Run users
1,487 outage reports in the last 24 hours
![]() Sindh, Pakistan
Sindh, Pakistan
Other
4 days ago
4 days ago
![]() England, United Kingdom
England, United Kingdom
Server not responding
4 days ago
4 days ago
![]() Karnataka, India
Karnataka, India
App not loading
6 days ago
6 days ago
![]() Ireland
Ireland
"unable to create new compute engine loadbalancer backend services(EXTERNAL_MANAGED). I keep getting 'BACKEND_ERROR' or 'the service X is not ready'"
9 days ago
9 days ago
![]() New York, United States
New York, United States
Service down
9 days ago
9 days ago
![]() Andhra Pradesh, India
Andhra Pradesh, India
Slow performance
11 days ago
11 days ago
![]() Telangana, India
Telangana, India
Sign in problem
12 days ago
12 days ago
![]() Lisbon, Portugal
Lisbon, Portugal
Service down
12 days ago
12 days ago
![]() Texas, United States
Texas, United States
"Firestore data timing out. Firebase Functions deployments failing"
13 days ago
13 days ago
![]() England, United Kingdom
England, United Kingdom
Other
14 days ago
14 days ago
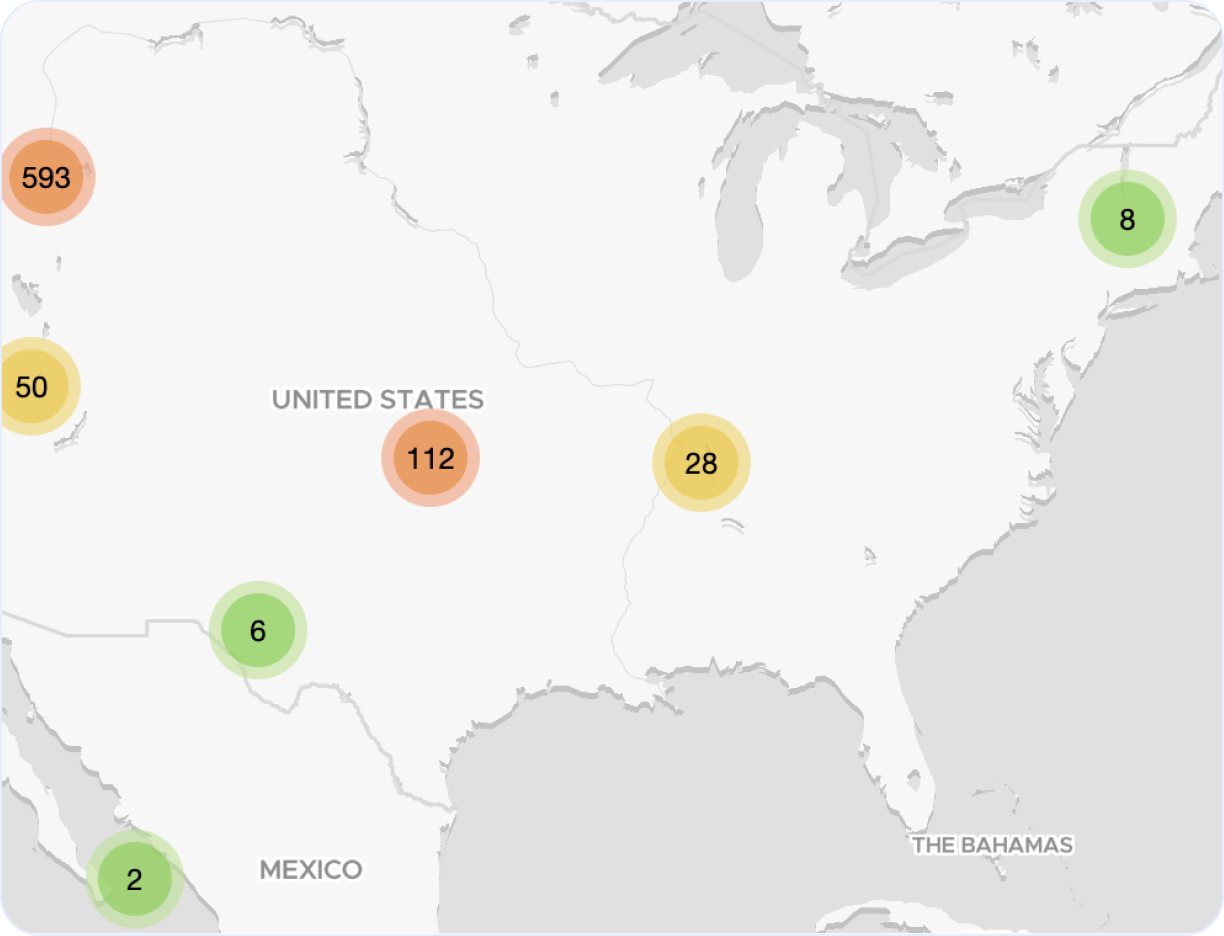
Cloud Run outage map
Explore our interactive Cloud Run outage map to monitor real-time incidents and service issues across the globe. This dynamic map highlights regions around the world affected by recent Google Cloud outages, giving you a clear view of performance and downtime trends.
Recently detected Google Cloud outages
| Incident description | Duration | StatusGator detected | Officially acknowledged |
|---|---|---|---|
| Google App Engine console unavailable | 4h 30m |
Never acknowledged
|
|
| BigQuery service outage | 34m |
Never acknowledged
|
|
| Gemini API and Vertex AI service outage | 1h 2m |
Never acknowledged
|
|
| Cloud Build jobs failing to start or stuck in queue | 19m |
Never acknowledged
|
|
| Locker Studio not loading | 2h 35m |
Never acknowledged
|
|
| Query results not displaying and error messages appearing | 38m |
Never acknowledged
|
|
| Looker Studio experiencing system errors and not loading charts | 1h 54m |
Never acknowledged
|
|
| Service connectivity and performance issues | 51m |
Never acknowledged
|
|
| Issues connecting to AppSheet. | 58m |
Never acknowledged
|
|
| Issues with Looker Studio dashboard loading and data retrieval | 5h 14m |
Never acknowledged
|
Incident description
Google App Engine console unavailable
Duration
4h 30m
StatusGator detected
Officially acknowledged
Never acknowledged
Incident description
BigQuery service outage
Duration
34m
StatusGator detected
Officially acknowledged
Never acknowledged
Incident description
Gemini API and Vertex AI service outage
Duration
1h 2m
StatusGator detected
Officially acknowledged
Never acknowledged
Incident description
Cloud Build jobs failing to start or stuck in queue
Duration
19m
StatusGator detected
Officially acknowledged
Never acknowledged
Incident description
Locker Studio not loading
Duration
2h 35m
StatusGator detected
Officially acknowledged
Never acknowledged
Incident description
Query results not displaying and error messages appearing
Duration
38m
StatusGator detected
Officially acknowledged
Never acknowledged
Incident description
Looker Studio experiencing system errors and not loading charts
Duration
1h 54m
StatusGator detected
Officially acknowledged
Never acknowledged
Incident description
Service connectivity and performance issues
Duration
51m
StatusGator detected
Officially acknowledged
Never acknowledged
Incident description
Issues connecting to AppSheet.
Duration
58m
StatusGator detected
Officially acknowledged
Never acknowledged
Incident description
Issues with Looker Studio dashboard loading and data retrieval
Duration
5h 14m
StatusGator detected
Officially acknowledged
Never acknowledged
Looking to track Cloud Run downtime and outages?
- Receive real-time status updates
- Show current status on private or public status page
- Be the first to know if service is down
- Keep your team informed
- Monitor alongside other services and websites
Recent Cloud Run outages and issues
Follow the recent outages and downtime for Cloud Run in the table below.
If you're experiencing a problem now, check the current Cloud Run status or
.
| Incident Name | Duration | Started | Severity |
|---|---|---|---|
|
We are investigating elevated error rates with multiple products in us-east1
|
1m |
Warn
|
|
|
We are investigating elevated error rates with multiple products in us-east1
|
342d 21h 8m |
Warn
|
|
|
We are investigating elevated error rates with multiple products in us-east1
|
1m |
Warn
|
|
|
We are investigating elevated error rates with multiple products in us-east1
|
1h 25m |
Warn
|
|
|
Multiple GCP products are experiencing Service issues
|
1m |
Down
|
Incident name
We are investigating elevated error rates with multiple products in us-east1
Duration
1m
Start
Severity
Warn
Incident name
We are investigating elevated error rates with multiple products in us-east1
Duration
342d 21h 8m
Start
Severity
Warn
Incident name
We are investigating elevated error rates with multiple products in us-east1
Duration
1m
Start
Severity
Warn
Incident name
We are investigating elevated error rates with multiple products in us-east1
Duration
1h 25m
Start
Severity
Warn
Incident name
Multiple GCP products are experiencing Service issues
Duration
1m
Start
Severity
Down
Get notified about Cloud Run outages
Stay updated with instant alerts for Cloud Run outages by signing up now!
See Cloud Run status on your status page
You can also monitor any service or website on your status page
Get notified about Cloud Run outages
Stay updated with instant alerts for Cloud Run outages by signing up now!
One App that has it all
With features designed to cover all your needs for monitoring and communicating outages or downtime, StatusGator keeps your team connected and informed. Stay updated on Cloud Run outages, potential problems, and its current status in real-time, ensuring you're always prepared to act.
Monitor Cloud Run along with other services and websites
StatusGator monitors over 9,450 cloud services, hosted applications, and websites. Just add what you need to the list, and we'll automatically aggregate their statuses into a single page. You'll receive notifications for any issues affecting you and your page subscribers.
Get notified on Cloud Run status change
StatusGator monitors all of your services and websites and sends your team instant notifications when they go down. Stay abreast of issues that affect your team with notifications: in email, Slack, Teams, or wherever your team communicates.
Show Cloud Run on your status page
Easily notify your end-users of outages using a customizable status page. Display cloud services or websites, as well as any custom monitors you add manually. Create multiple status pages tailored to different needs, customize them, and embed them for maximum effectiveness.
Users who monitor Cloud Run status also follow these services












About our Cloud Run status page integration
Cloud Run (Cloud computing services for business challenges by Google Cloud) is a a Cloud Infrastructure solution that StatusGator has been monitoring since August 2016. Over the past almost 10 years, we have collected data on on more than 2,616 outages that affected Cloud Run users. When Cloud Run publishes downtime on their status page, they do so across 209 components using 3 different statuses: up, warn, and down which we use to provide granular uptime metrics and notifications.
If you're wondering, "Is Cloud Run down?", or need to know its current status, we've got you covered. Our platform tracks every reported outage, performance issue, and maintenance window to ensure you're informed. Whether Cloud Run is experiencing a problem now or has recently resolved one, our detailed history keeps you updated.
More than 2,900 StatusGator users monitor Cloud Run to get notified when it's down or has an outage. This makes it one of the most popular Cloud Infrastructure services monitored on our platform. We've sent more than 447,900 notifications to our users about Cloud Run incidents, providing transparency and peace of mind. You can get alerts by signing up for a free StatusGator account.
-
Early Warning Signals
If we detect a potential Cloud Run outage or other issue before it was reported on the official status page we will send an Early Warning Signal notification to StatusGator subscribers. We can often detect issues before they are officially acknowledged by the provider, giving you a head start on resolving any potential problems.
-
Down Notifications
If Cloud Run is having system outages or experiencing other critical issues, red down notifications appear on the status page. In most cases, it means that core functions are not working properly, or there is some other serious customer-impacting event underway.
-
Warning Notifications
Warn notifications are used when Cloud Run is undergoing a non-critical issue like minor service issues, performance degradation, non-core bugs, capacity issues, or problems affecting a small number of users.
-
Maintenance Notifications
Cloud Run does not post separate notifications for planned maintenance work so we are unable to send notifications when maintenance windows begin. If you need Cloud Run maintenance notifications, please email us.
-
Status Messages
When Cloud Run posts issues on their status page, we collect the main headline message and include that brief information or overview in notifications to StatusGator subscribers.
-
Status Details
When Cloud Run has outages or other service-impacting events on their status page, we pull down the detailed informational updates and include them in notifications. These messages often include the current details about how the problem is being mitigated, or when the next update will occur.
-
Component Status Filtering
Because Cloud Run has several components, each with their individual statuses, StatusGator can differentiate the status of each component in our notifications to you whenever a particular component is down. This means, you can filter your status page notifications based on the services, regions, or components you utilize. This is an essential feature for complex services with many components or services spread out across many regions.
Get notified about Cloud Run outages
Stay updated with instant alerts for Cloud Run outages by signing up now!
Looking for Downdetector Cloud Run alerts?
Both official and crowdsourced updates for Cloud Run outages.
StatusGator
Downdetector
More than 9,450 services monitored.
StatusGator
Downdetector
Proactive alerts on Cloud Run status changes sent to your Slack, Microsoft Teams, and more.
StatusGator
Downdetector
Monitoring of both Cloud Run and your own apps.
StatusGator
Downdetector
Granular monitoring of Cloud Run components.
StatusGator
Downdetector
Frequently asked questions
Can't find your question? Email us to arrange a time to discuss. We'd love to chat!